1 - Overview
BrithSpark - a continerized compute engine for all your needs.
BrightSpark is a compute engine that combines AWS Elastic Container Service and AWS Elastic Kubernetes Service fronted by APIs.
BrightSpark is a cost-effect, fully managed compute engine. It is ideal replacement for traditional compute engines for tasks such as processing large volumnes of data, running machine learning or handling incoming streaming data. It is built entirely on containers to allow maximum flexibility for the developer.
Try answering these questions for your user in this page:
What is it?
It’s a compute engine, controlled by APIs. It runs in your company account to keep data secure thereby offering your organisation a wide range of capabilities of compute. Whether you want to optimize for cost, or improve speed, BrightSpark offers your development teams a variety of options, from running on AWS Fargate to EC2. All this without your teams needing to manage any of the infrastructure.
Now they don’t have to worry about Kubernetes, AWS EMR clusters, AWS Glue or any other engine - they can simply tell BrightSpark their job-name, provide parameters and submit the job to run. BrightSpark handles all the complexity to make the compute happen.
Best of all, built into BrightSpark is all the management reporting you need as a leader. Questions such as:
- “How much have these jobs cost the organisation over the last 7 days?”,
- “What are the most expensive jobs we’re currently running?”, or
- “Over the lifespan of these 20 jobs, how much have they cost and what is the least efficient job?”
All of this is built into BrightSpark at no extra cost to you.
Why do I want it?
Compute cost is the biggest driving factor for most organisations and it is getting worse as companies drive more Machine Learning, Generative AI and other data driven requirements. BrightSpark aims to reduce these costs for the customer.
What problems does it solve?
Cost: AWS costs are driving up organisational costs and with everything in the cloud, many companies didn’t bargin on their compute costs being this high. We see anywhere between 50% and 90% savings over jobs running on AWS Glue.
Ease: Most engineering organsations - especially in the data engineering world - are constantly striving to reduce complexity. Data and machine learning pipelines, data scientists notebooks, job development all add significant complexity. BrightSpark’s API first approach, simplifies these by ensuring engineers can worry about their code. BrightSpark takes care of where that code runs, how it’s reported and the costs associated with the runs.
Speed: Depending on the compute option that’s chosen, BrightSpark jobs can be optimised for cost or speed - sometimes both. If the developer chooses speed, they can run the jobs on EC2 without having to manage ANY EC2 instances. Alternatively, they may choose to run the jobs on Fargate - sacrificing speed for sometimes, astonishingly reduced cost.
Versitlity: If you implement BrightSpark, it’s implemented for the whole organisation. Since BrightSpark runs in your account, you data are secure - never leaving your organisation. What this means is that whether you’re a data engineer in the platform space, or a data scientist in the descision space, all your engineers can use BrightSpark and take advantage of the cost savings.
Diverity: Compute engines are good for so many things, whether you’re dealing with Jupyter Notebooks, heavy-duty Apache Spark, intense Python compute, or needing to manage moving files to AWS Glacier Deep Archive, you can use the same compute engine across your organisation for a variey of jobs.
Reporting/management: Built into every BrightSpark job is reporting. In fact it’s not been added as an afterthought, it was built with management in mind from day one. We believe that reporting goes beyond reporting on a single job. We allow our customers to tag jobs with multiple tags and report based on those tags. An example may be: The marketing department requires 3 or 4 jobs to make up a campaign. Those different jobs can be tagged with the same campaign tag and later, they can pull a report showing the costs of the campaign. Equally, the engineer may want to investigate the slowest running jobs to apply improvements. This sort of reporting is built into BrightSpark.
So what can’t it do?
What is it good for?: As of today, it can handle Python jobs - a direct replacement for running those jobs on AWS Glue.
What is it not good for?: Scala is currently not supported for our automated code changes, so if you have a Scala job, you would need to make changes in your code to allow it to run on BrightSpark.
What is it not yet good for?: Two feature that many customers are wanting are some method of handling data quality and data lineage. To address those, we’re in the process of building Apache Expectations and Spline into BrightSpark to allow customers to address these two significant data processing challenges.
Unlike other companies, we like to keep things simple. As a result we’re not adding loads of overhead to the product that you may never use. Without those complexities, you don’t have to pay for “features” you never use!
Where should I go next?
Run-time graphs of cost savings.
2 - Example of runtimes
On this page, you can judge for yourself on the costs savings and performance improvements
Real job runs and associated costs.
In the following example jobs, we used approximately 20GB of S3 Storage Lens data. This encompassed about a years worth of data from a large datalake. We did some transformations of the data (such as anonymising the data) as well as computed averages, means, maxes, etc.
The jobs were split into a single days worth of data, to a week, a month, 6-months and a years worth of data, each time performing the same jobs on BrightSpark and then on AWS Glue for comparison.
We ran these jobs many times and the graphs represent an average of runtimes.
1 day’s worth of data
This is a small job. It was run on a small BrightSpark t-shirt size size (2 vCPU, 8GB RAM containers). For AWS Glue, the job was run with the smallest DPUs available: 2 x G.1X.
The data we used for the tests was about 7.5GB.
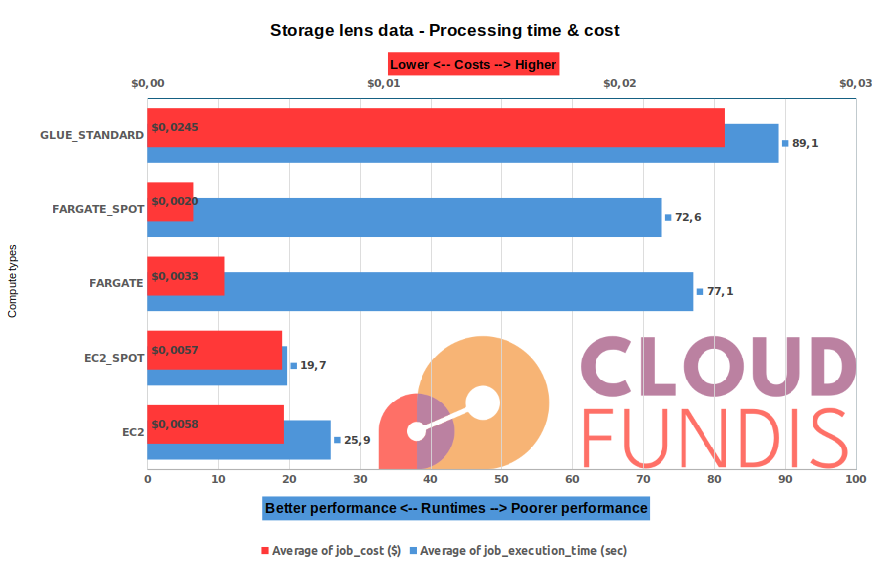
| Observations (all observations are relative to AWS Glue) |
|---|
- Fargate spot is the cheapest form of compute, reducing costs by 92%
- However using Fargate spot, compute runtime was only 18% faster than AWS Glue
- Savings range from $2.1c to $2.2c per job
- Running on EC2, the savings are smaller [red] ($1.8c), however compute time [blue] is considerably faster (>70% performance improvement over AWS Glue)
|
| Conclusions |
|---|
- If you need your jobs completed fast, choose EC2 or EC2 Spot
- If you want to achive maximum savings, use Fargate or Fargate Spot, but at the expense of speed
|
1 week’s worth of data
This is a medium job. It was run on a medium BrightSpark t-shirt size (2 vCPU, 8GB RAM containers). For AWS Glue, the job was run with the smallest DPUs available: 2 x G.1X.
The data we used for the tests was about 7.5GB.
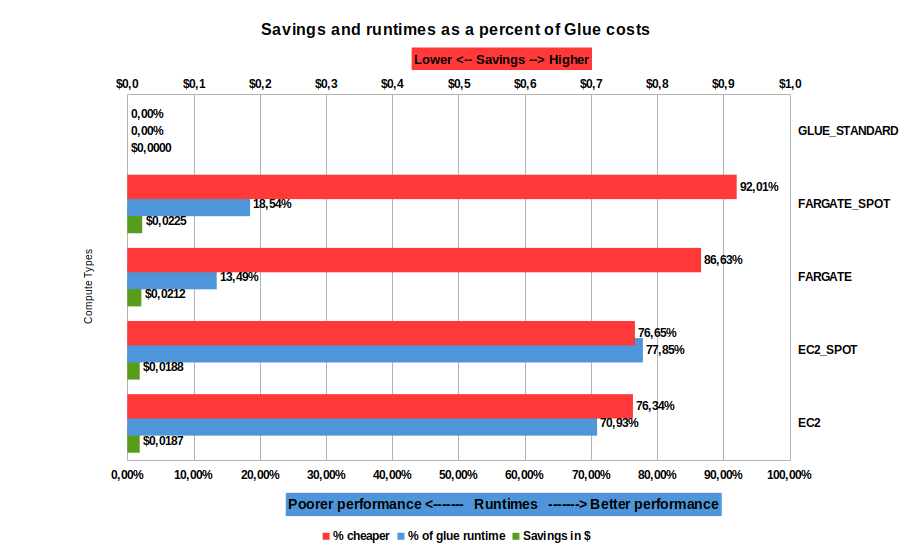
| Observations (all observations are relative to AWS Glue) |
|---|
- Fargate spot is the cheapest form of compute, reducing costs by 95%
- Fargate and Fargate spot, compute runtime has a 35% performance improvement over AWS Glue
- Savings range from $2.6c to $2.9c per job
- Running on EC2, the savings are smaller [red] ($2.1 to 2.2c), however compute time [blue] is considerably faster (>80% performance improvement over AWS Glue)
|
| Conclusions |
|---|
- If you need your jobs completed fast, choose EC2 or EC2 Spot
- If you want to achive maximum savings, use Fargate or Fargate Spot, but at the expense of some speed over EC2
|
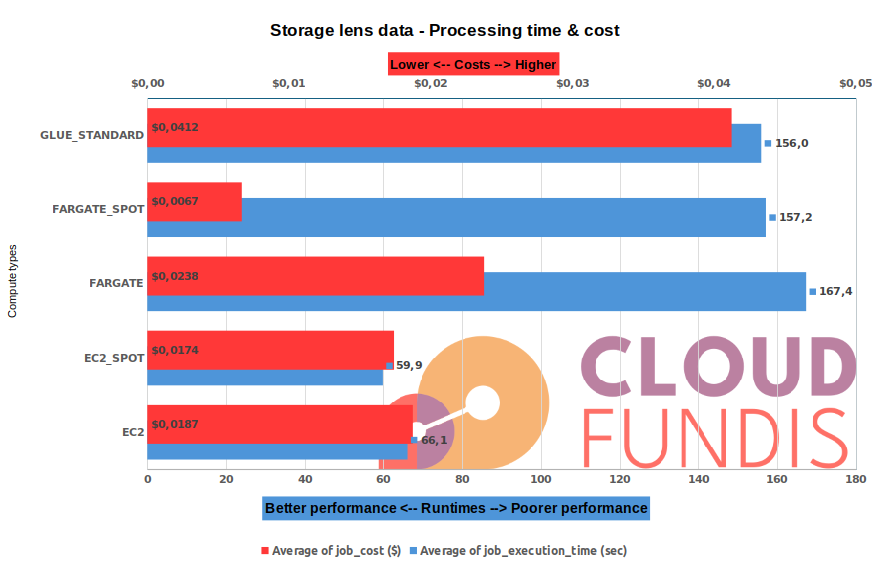
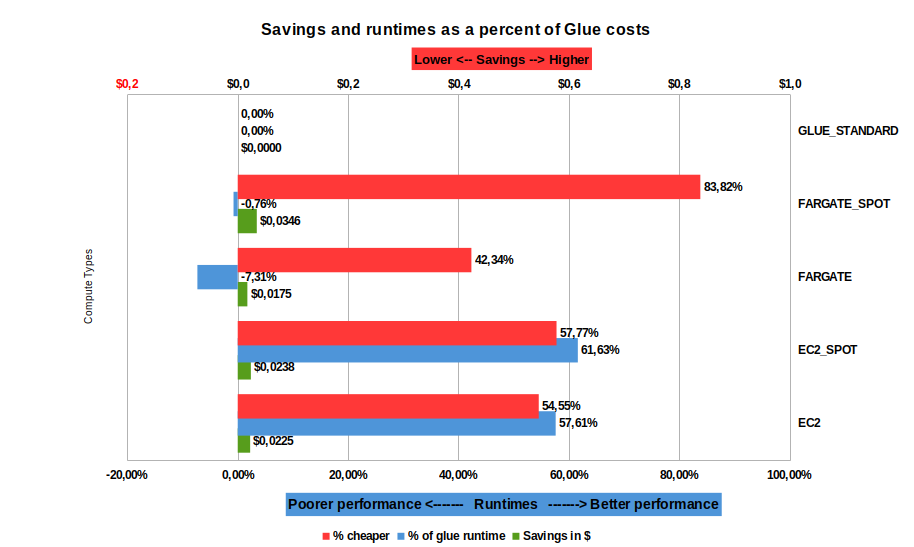
1 month’s worth of data
This is a large job. It was run on a large BrightSpark t-shirt size (2 vCPU, 8GB RAM containers). For AWS Glue, the job was run with the smallest DPUs available: 2 x G.1X.
The data we used for the tests was about 15GB.
| Observations (all observations are relative to AWS Glue) |
|---|
- Fargate spot is the cheapest form of compute, reducing costs by 83%. However, choosing this option shows a drastic performance degradation for this larger dataset
- Both Fargate and Fargate spot, compute runtime has degraded significantly over AWS Glue
- Savings are maximized at $3.4c but choosing savings over runtime is not advised
- Running on EC2, the savings are smaller [red] ($2.2 to 2.3c), however compute time [blue] is consistently faster (>57% performance improvement over AWS Glue)
|
| Conclusions |
|---|
- For larger jobs, don’t choose Fargate. Instead choose EC2
- If you need your jobs completed fast, choose EC2 or EC2 Spot
- If you want to achive maximum savings, use Fargate or Fargate Spot, but at the expense of some speed over EC2
|
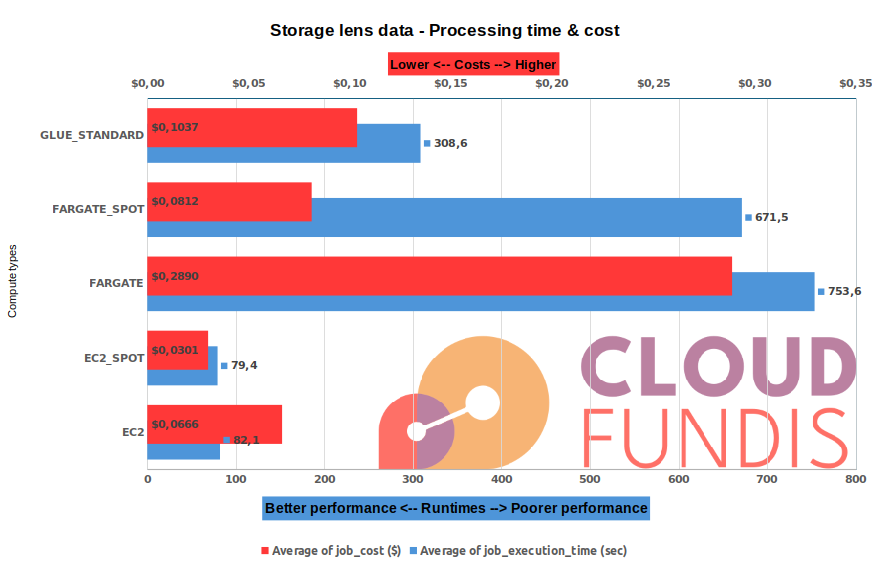
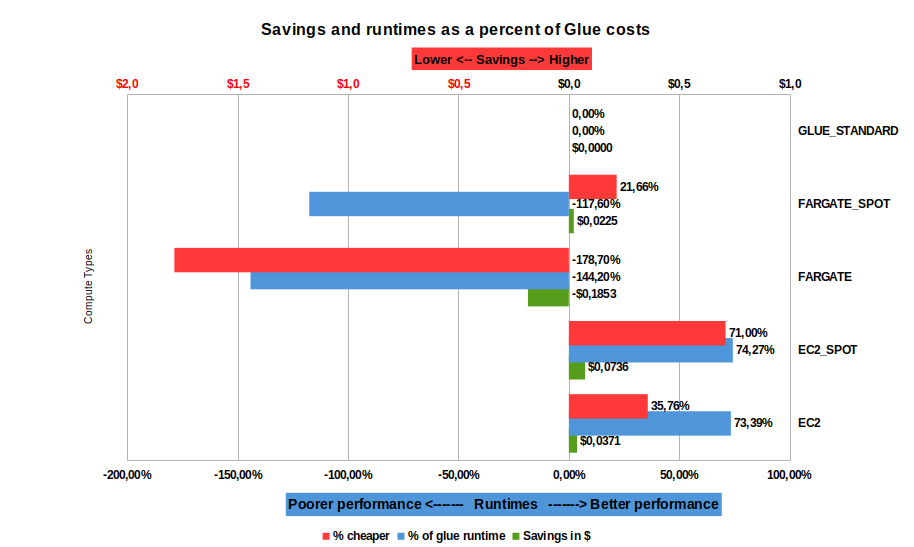
6 months worth of data
This is a large job. It was run on a large BrightSpark t-shirt size (2 vCPU, 8GB RAM containers). For AWS Glue, the job was run with the smallest DPUs available: 2 x G.1X.
The data we used for the tests was about 15GB.
| Observations (all observations are relative to AWS Glue) |
|---|
- Using Fargate is both more expensive than AWS Glue and performs significatly worse too. We strongly advise that you choose only EC2 for all your compute at this (or larger) size data
- Fargate spot is not much better (cheaper, but still terrible performance!)
- Savings are maximized at $7.3c by using EC2 spot
- Running on EC2, the compute time [blue] is consistently faster (>73% performance improvement over AWS Glue)
|
| Conclusions |
|---|
- For larger jobs, don’t choose Fargate. Instead choose EC2
- If you need your jobs completed fast, choose EC2 or EC2 Spot
|
1 year’s worth of data
This is a extra-large job. It was run on a extra-large BrightSpark t-shirt size (2 vCPU, 8GB RAM containers). For AWS Glue (Flex), the job was run with the smallest DPUs available: 2 x G.1X.
The data we used for the tests was about 15GB.
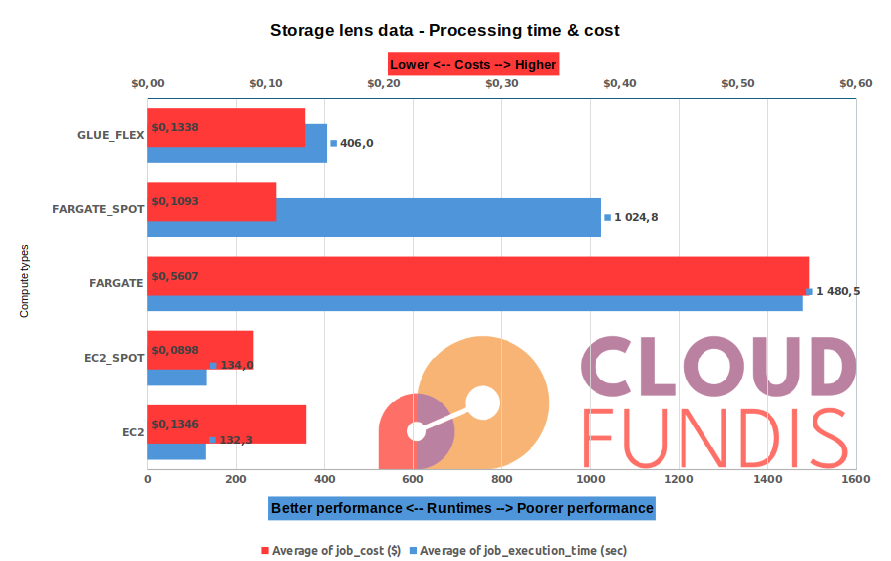
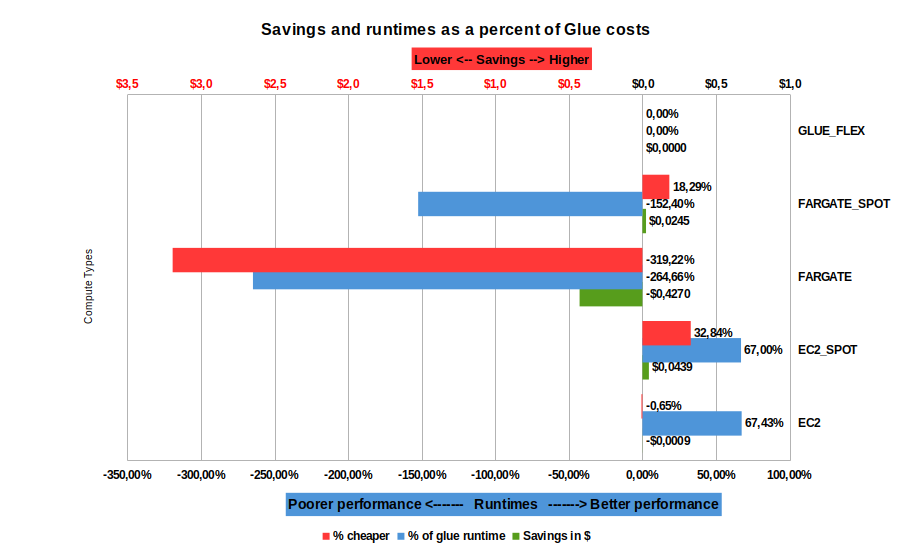
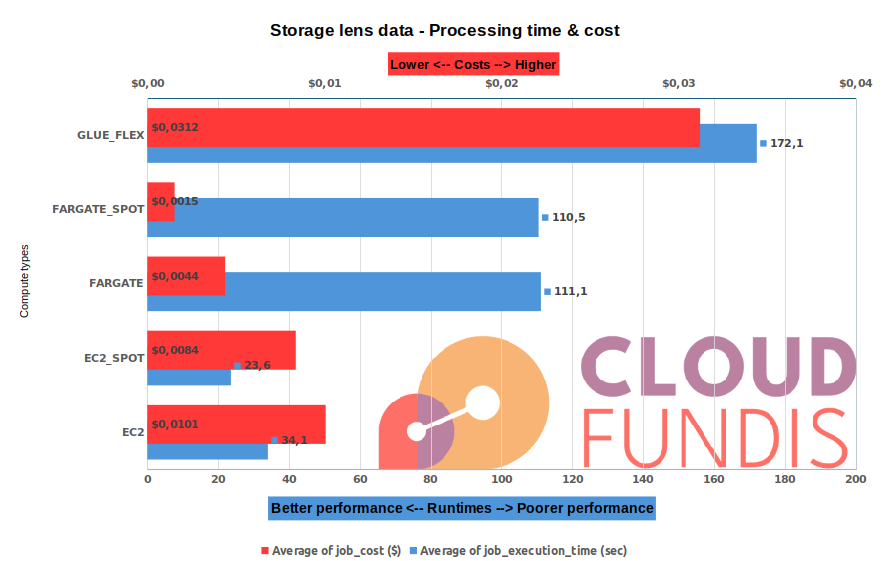
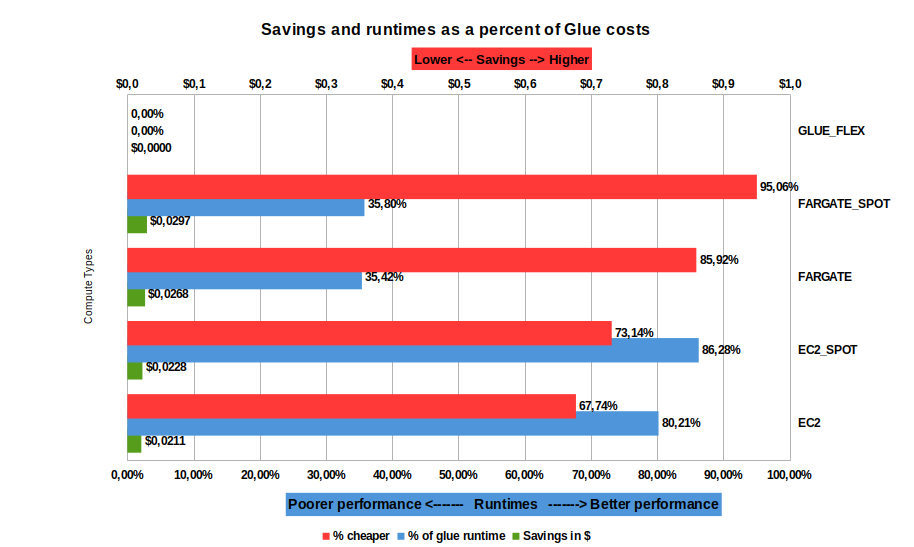
| Observations (all observations are relative to AWS Glue - Flex in this case) |
|---|
- Using Fargate is both more expensive than AWS Glue and performs significatly worse too. We strongly advise that you choose only EC2 for all your compute at this (or larger) size data
- Fargate spot is not much better (cheaper, but still terrible performance!)
- Savings are maximized at $4.3c by using EC2 spot
- Running on EC2, the compute time [blue] is consistently faster (>67% performance improvement over AWS Glue Flex)
|
| Conclusions |
|---|
- For larger jobs, don’t choose Fargate. Instead choose EC2
- If you need your jobs completed fast, choose EC2 or EC2 Spot
- It is still preferebable to use BrightSpark over using AWS Glue Flex
|
3 - Getting Started
What does your user need to know to try your project?
This is a placeholder page that shows you how to use this template site.
Information in this section helps your user try your project themselves.
What do your users need to do to start using your project? This could include downloading/installation instructions, including any prerequisites or system requirements.
Introductory “Hello World” example, if appropriate. More complex tutorials should live in the Tutorials section.
Consider using the headings below for your getting started page. You can delete any that are not applicable to your project.
Prerequisites
Are there any system requirements for using your project? What languages are supported (if any)? Do users need to already have any software or tools installed?
Installation
Where can your user find your project code? How can they install it (binaries, installable package, build from source)? Are there multiple options/versions they can install and how should they choose the right one for them?
Setup
Is there any initial setup users need to do after installation to try your project?
Try it out!
Can your users test their installation, for example by running a command or deploying a Hello World example?
3.1 - Example Page
A short lead description about this content page. It can be bold or italic and can be split over multiple paragraphs.
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90’s four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven’t heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
- This is an unordered list following a header.
- This is an unordered list following a header.
- This is an unordered list following a header.
- This is an ordered list following a header.
- This is an ordered list following a header.
- This is an ordered list following a header.
| What | Follows |
|---|
| A table | A header |
| A table | A header |
| A table | A header |
There’s a horizontal rule above and below this.
Here is an unordered list:
- Liverpool F.C.
- Chelsea F.C.
- Manchester United F.C.
And an ordered list:
- Michael Brecker
- Seamus Blake
- Branford Marsalis
And an unordered task list:
And a “mixed” task list:
And a nested list:
- Jackson 5
- Michael
- Tito
- Jackie
- Marlon
- Jermaine
- TMNT
- Leonardo
- Michelangelo
- Donatello
- Raphael
Definition lists can be used with Markdown syntax. Definition headers are bold.
- Name
- Godzilla
- Born
- 1952
- Birthplace
- Japan
- Color
- Green
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin’ Somethin’, Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let’s Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I’m a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She’s Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.

Large images should always scale down and fit in the content container.

The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Components
Alerts
This is an alert.
Note
This is an alert with a title.Note
This is an alert with a title and Markdown.This is a successful alert.
This is a warning.
Warning
This is a warning with a title.Another Heading
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This Document
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Pixel Count
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
External Links
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
4 - Concepts
What does your user need to understand about your project in order to use it - or potentially contribute to it?
This is a placeholder page that shows you how to use this template site.
T-shirt sizes
In BrightSpark, we define the concept of a t-shirt size to jobs. What this means is that jobs are categorized into small (S), medium (M), large (L), extra-large (XL), [and so forth] sized jobs. Running a job on a small t-shirt size might be 2 vCPUs and 8GB RAM while an XL may be 1 vCPUs and 128GB RAM. This allows one to define, in granular detail, the size of compute for a job.
Just like in other compute engines, specifying large compute for a small job, s wasteful of both compute and money. We encourage engineers to accurately specify their compute sizes.